你的 AI 不是不夠聰明,是你管太多:Code with Claude London Day 2 全 13 場,給電商老闆的三條 AI 治理


你有沒有過這種經驗。
剛開始用某個 AI 工具的時候,它意外地好用。然後你想讓它更好,於是多寫了一條規則。又遇到一個漏洞,再補一條。再來一個例外狀況,又補一條。三個月後,你回頭看那段 prompt,已經長到自己都不想讀,而 AI 呢?反而越來越笨,越來越常給你莫名其妙的答案。
如果你問我,這幾乎是每個認真用 AI 的人都會踩的坑。
Anthropic 前陣子把開發者大會「Code with Claude」開到了倫敦。我之前把第一天的 24 場演講整理成一篇導覽,那是「現況盤點」,台上的人在講模型進化到哪、產業瓶頸移到哪,比較像產業 keynote。想補課的可以先看那篇 Day 1 全 24 場筆記。
這篇要講的是第二天,跟 Day 1 不同天。
第二天不一樣。Day 2 是 13 場 hands-on workshop,工程師捲起袖子、打開電腦,現場一行一行示範「我們到底怎麼把 agent 真的做上線」。我把這 13 場全部看完,本來以為會是 13 個不相干的 demo:有人做庫存、有人做簡報、有人查洗錢、有人寫專利、有人篩履歷,甚至還有一場是在 Minecraft 裡挖鑽石。
結果把它們疊在一起看,浮出了三條反覆出現的母題。
而這三條,剛好就是現在每個中小電商老闆、行銷主管最需要的「AI 治理」。我把它整理成三句話,等下一條一條拆給你看:
- 母題 A:少即是多,別過度約束。 你的 AI 會壞,多半是你「加太多」。
- 母題 B:Evals 跟 Traces,是 agent 的 TDD。 別憑感覺,要憑指標跟軌跡。
- 母題 C:高風險的事要「協作」,不要「全自動委派」。 人要留在迴路裡、過程要可溯源。
你遇到 AI 不靈的時候,本能反應通常是三件事:再加規則、憑感覺驗收、想全自動省人力。
這三件事,Day 2 第一線的人,反覆在做相反的。
母題 A:少即是多,你的 AI 會壞多半是你加太多
先講最打臉的一個案例,因為它有數字。
Anthropic 應用 AI 工程師 Will 在「Tool, skill, or subagent?」這場,拆解了一個叫「StockPilot」的庫存管理 agent。這東西一開始只為解決一個小問題,但你知道後來怎麼了。業務需求一直加,這裡要管促銷、那裡要算庫存、又要接報表,於是它的 system prompt 一路膨脹到 400 行,掛了 12 個工具,其中還有 3 個是「包成工具的子 agent」。
結果它越來越不可靠。最離譜的一次,prompt 裡有兩條政策互相打架,模型在算促銷的時候,把正確的 3.1 倍係數算成了 13.5 倍。
Will 做了一件很反骨的事:砍掉重練。system prompt 從 400 行砍到 15 行,工具從 12 個砍到 3 個(就是最基本的 bash、read、write),原本塞在 prompt 裡的一大堆業務邏輯,全部改用「Skills(技能包)」按需載入。
砍完之後,這個 agent 的 eval(評估通過率,等於它答對的比例)從 62% 一路衝到 92%,連 token 用量跟成本都一起降下來。

我得先把話講清楚:這個 62% 到 92% 是 StockPilot 這一個案子的數字,不是每個 agent 砍完都會這樣。別拿這個去打包票。
但它揭開的那個機制,值得每個天天用 AI 的人記在心裡。剛剛那個 3.1 被算成 13.5 的烏龍,有個專有名詞叫「上下文污染(context pollution)」:你的 prompt 寫越長,裡面互相矛盾的指令就越多,而你自己往往沒發現,模型就被這堆雜訊搞糊塗了。
這就像你請了一個新人,工作守則發給他厚厚 400 條,裡面第 38 條跟第 211 條還互相衝突。你覺得他會做得更好,還是更不敢動手?守則砍到一頁核心,人反而動得起來。AI 一模一樣。prompt 就是 AI 的工作守則。
而且不只 StockPilot 這一場在講「砍」。Day 2 至少有五場,從不同角度撞上同一件事:
Managed Agents 在做「解耦」。 Anthropic 的 Isabella 在「Ship your first Managed Agent」示範,把一個 agent 的「大腦」(Agent Loop,負責推理)跟「雙手」(Environment,負責執行工具)拆開來。光是這個解耦,P95 首字延遲(TTFT,你按下送出到它吐第一個字的時間)就降了超過九成。少把兩件事黏在一起,反而更快。
Arna 在講「別過度約束」。 Anthropic 架構師 Arna 在「How we Claude Code」這場講了一個我很認同的觀念:模型越強,你越不該把規格事先寫死,而是讓 Claude 主動反問你、自己去萃取需求。硬把每個細節都框死,反而是在綁住一個比你想像中更會自己想的工具。這呼應了 AI 圈那個有名的「苦澀的教訓(Bitter Lesson)」:別老想用人工規則去教模型,給它空間它做得更好。
Omni 在做「整合大腦」。 數據分析平台 Omni 的 CTO 在「Building the best agentic analytics harness」分享了他們的分析 agent「Blobby」。它原本一個外層 agent 規劃、再派一個 SQL 子 agent 去寫查詢,兩顆腦分開。聽起來很合理對吧,分工嘛。結果這個分工造成一堆無法預測的失敗,他自嘲是「分裂大腦(split brain)」。後來做了一輪重構,名字取得很傳神叫「Blobotomies(大腦手術)」,核心動作就是把腦「整合回去(consolidate the brain)」,讓單一一個 agent 同時掌握所有資訊跟工具,這才穩定下來。子 agent 不是越多越好,多一層分工,就多一層溝通會斷掉的風險。
Warp 在用「原則」取代「規則」。 Warp 的 Petra 在「Teaching agents to learn from your team」介紹他們的 agent「Buzz」,講了一個關鍵:別用「僵硬規則(Rules)」,要用「原則(Principles)」。規則很脆,遇到一個你沒定義過的新狀況就當機;原則給的是一套判斷邏輯,反而走得遠。
Metaview 把規則丟了,改寫一頁畫像。 Metaview 的 Nick Mayhew 在做履歷篩選,原本想用一堆規則、加權、流程圖去定義「好候選人」,後來全部放棄,改用一頁自然語言的 Markdown 寫「理想候選人畫像(ICP)」。一頁白話文,比一張複雜流程圖好用。
你發現了嗎,這六場講的是同一件事。
少即是多。先把雜訊清乾淨,再談要不要加東西。
那「砍掉的東西去哪了」?這就帶到 Day 2 反覆出現的另一個觀念,漸進式揭露(progressive disclosure)。意思是:別把所有資訊都常駐塞在 prompt 裡,而是需要用到的時候才把它拉進來。Anthropic 在 2025 年底把「Agent Skills」做成開放標準,後來 OpenAI、Google、GitHub、Cursor 都跟進。根據 Anthropic 的工程說明,這套機制有個很驚人的數字:17 個 skill 合計只占大約 1,700 個 token,讓一個 agent「知道」有幾十個技能可以用的成本,比啟用其中單一一個還低。
換句話說,與其把一份肥到 400 行的 prompt 整天扛在身上,不如讓它平常輕裝上陣,遇到特定任務再去翻對應的那一頁。又省又準。
母題 B:別憑感覺,Evals 跟 Traces 是 agent 的 TDD
砍完之後問題來了:你怎麼知道砍對了?
這就是 Day 2 第二條母題。一句話:別再憑「感覺它好像變好了」做決定。
寫過程式的人都知道 TDD(測試驅動開發):先寫好測試,定義「怎樣算對」,再來寫程式。Day 2 好幾場不約而同把這套搬到 agent 上。
「Evals for taste」這場最直接,講的是一個投影片生成 agent。投影片好不好看很主觀對吧?講者偏要把這種「感覺怪怪的」變成可以量化、可以一題一題打勾的指標。他還提了一個我覺得很重要的細節:評分的時候,別讓 AI 先給分數,因為一旦給了分,它後面就會替自己那個分數辯護(這叫錨定效應)。正確做法是先把正反論點都列出來,最後才打分。另外他也驗證了一件事:強模型配簡單提示,往往比弱模型配大量調校還好。
StockPilot 那場 Will 用的方法叫「hill-climbing on evals(在評估上爬坡)」:先建一個基準分數,動一下架構,重跑一次評估,看分數有沒有往上爬。不是憑直覺改,是看著數字改。
更狠的是反洗錢那場。Quanto FinTech 的 Stefano Amorelli 在「Fighting financial crime with Claude Cowork」直接講了一句:「Evals = TDD」。他們做的是用 AI 當查洗錢的「第二道防線」,這種事錯不得,所以專案一開始就先建好量化指標:工具有沒有呼叫對、推理過程對不對、結果可不可以溯源。先定義對錯,再開工。
而 Omni 那位 CTO 補了一句我最喜歡的話:「我最看重的不是分數,是完整的 traces(追蹤軌跡)。」分數只告訴你考幾分,traces 告訴你它「為什麼」這樣答,你才找得到根因去修。
連最好玩的一場都是這個道理。「Agent Battle」是現場辦的競賽,45 分鐘內調你的 agent 設定,去 Minecraft 裡挖最多鑽石,平手的話比誰 token 效率高。聽起來像玩遊戲,但那個「設定、跑、看結果、再調」的迴圈,跟你在生產環境裡做 AI 開發是一模一樣的。
翻成老闆聽得懂的話就一句:
先講清楚「怎樣才算做得好」,再來談調。
母題 C:越貴、越不可逆的事,越不能全自動委派
第三條母題,是 Day 2 我覺得最該講給老闆聽、但最容易被忽略的一條。
很多人想用 AI 的終極幻想是「全自動」,丟給它、人就不用管了。Day 2 第一線做高風險場景的人,全都在踩煞車。
寫專利的 Solintelligence,Olly Cobb 在「Where code meets court」講得最白:高風險的決策,需要的是「協作(collaboration)」,不是「委派(delegation)」。專利寫錯,可能好幾年後在法庭上才爆,這種事你不可能全交給 AI 跑完就算。所以他們把「引用來源(citations)」當成一等公民,模型給你建議的同時,必須附上明確的出處讓律師審,人保留最終裁量權。
反洗錢那場也一樣,AI 是「第二道防線」不是唯一防線,目標是從 human-in-the-loop(人在迴路裡)慢慢走到 human-on-the-loop(人在迴路上監督),而且全程可溯源、不能有幻覺。
做科學研究工具的 Elicit,James Brady 在「Making agentic workflows trustworthy」講了一句我很喜歡的話:「機制決定信任。」你要信任 AI 的產出,得先看得懂它是「怎麼」生出來的。他們乾脆自己造了一套叫 AshPL 的小語言,刻意設計成「不能亂跑」(圖靈不完備、純函數、不准偷改狀態),讓 agent 每一步檢索、過濾、推理都攤在陽光下,人看得懂、別的 agent 也驗得了。翻成白話就是:別讓 AI 在一個你看不進去的黑盒裡幫你做高風險決策,過程要能攤開、能重播,你才敢信它。
履歷篩選的 Metaview 講得更傳神:AI 在這裡的角色是「學徒(apprentice)」,不是決策者。它可以根據面試官的行為自動去迭代那份候選人畫像,但調整後的版本一定要人確認過才算數。
連 Warp 都是。Buzz 這個 agent 自己學會了一個改進,它不會偷偷就改下去,而是把改進包成一個 PR(程式碼變更請求)交給人審核。
你看出共通點了嗎。
越貴、越不可逆的事,越不能全自動委派。 金流、法務、對外溝通這種錯一次就回不來的事,AI 可以當你的學徒、你的第二道防線、你的草稿手,但那支簽核的筆,要留在人手上。
順帶一提:你的 agent 會從團隊身上學
Day 2 還有一條暗線,原本我沒打算單獨講,但它對未來太重要,補一小段。
Anthropic 的 Kevin 在「Agents that remember」示範了兩個東西。一個叫「Memory Store(記憶庫)」,是類似檔案系統的持久記憶,掛載進對話,讓 agent 可以自由讀寫、把這次學到的東西留給下次。另一個叫「Dreaming(作夢)」,是讓 agent 在離線的時候,非同步地把記憶庫整理、去重、查核、融會貫通一次。
Kevin 提到這個作夢流程的快取命中率(cache hit)約 95%,並且未來有可能比照批次 API 給折扣。注意,這是「未來可能」,不是現在已經拍板的政策,別當定論。
但方向很清楚:agent 不再是每次對話都從零開始的金魚腦,它會記得、會整理、會從你跟團隊的互動裡慢慢長出自己的判斷。前面 Warp 的 emoji 回饋、Metaview 的自動迭代,講的都是同一件事的不同切面。
行銷人的重頭戲:AirOps 怎麼把這三條母題用在內容行銷上
前面那些聽起來都很工程。我知道你想問:我一個賣東西、做行銷的,這跟我有什麼關係?
Day 2 有一場是專門講給你聽的。
AirOps 在「How AirOps chases friction」示範了一套 AI 內容行銷工作流,從「發現主題 → 研究 → 撰稿 → SEO/AEO」一條龍。注意,它不是按一個鍵就生出整篇文章那種,而是在每個關鍵節點都插了 human-in-the-loop(讓人介入),該你拍板的地方它會停下來等你。
而且他們做的每一個設計,剛好把上面三條母題全用上了:
母題 A(少即是多)的應用。 他們用一個「自然語言 Playbook 建構器」,讓行銷人用寫文件的方式去定義工作流,不用會寫程式,又保有每個節點的透明度。同時他們很怕「上下文污染」,所以設計了一個「品牌知識庫子代理」:流程一開始就先把品牌資訊抓好、存成一份 Artifact(產出物),後面所有步驟都讀這一份,避免主代理每一步都重新呼叫一次、結果不同步驟拿到版本不一樣的品牌調性。把「合規檢查」跟「內容撰寫」拆給各自專注的子代理之後,token 用量降了大約 8%,原本要 20 次工具呼叫的事變成 1 個入口。(這個 −8% 是 AirOps 這個案子的數字,不是通用保證。)
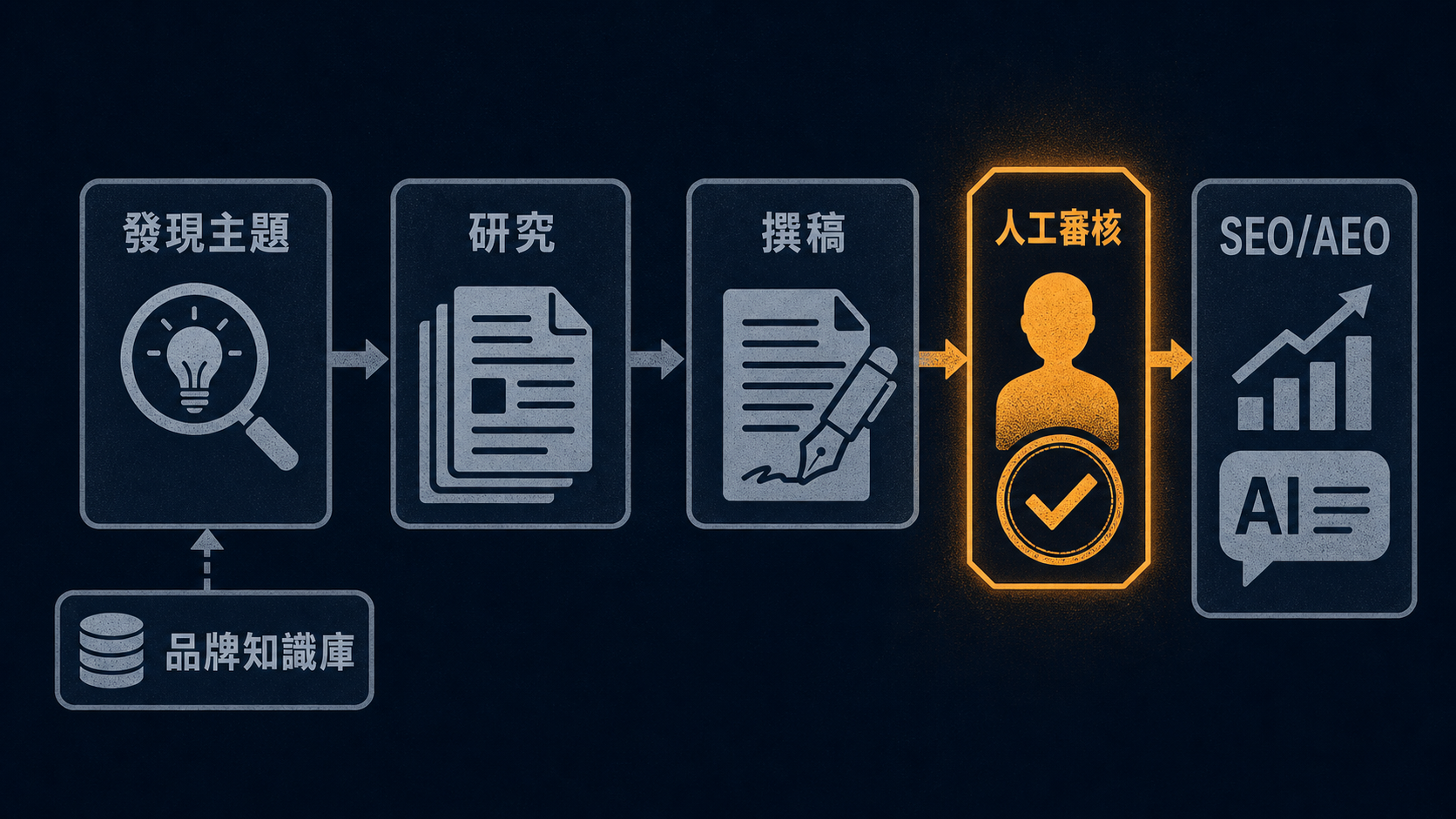
母題 C(協作不委派)的應用。 整套流程不是讓 AI 全自動發文,關鍵節點都留人審。他們的 beta 有 10 家企業客戶,兩週內就開始自主發布。團隊的心法很妙,叫「持續追逐摩擦點(chase friction)」:哪裡卡卡的、哪裡讓人不爽,就去那裡優化。
這裡面有個詞你要記住:AEO(答案引擎優化,Answer Engine Optimization)。
以前你做內容,目標是讓 Google 把你排到搜尋結果第一頁(這是 SEO)。
現在多了一層:要讓 ChatGPT、讓 AI 摘要在回答使用者問題的時候,直接引用你的內容。這就是 AEO。消費者越來越習慣直接問 AI「哪個牌子的除濕機好」,而不是自己滑十個連結。你的內容能不能被 AI 挑去當答案,正在變成新的流量入口。
那台灣電商怎麼開始?把母題 A、B、C 套上去就好:
別想著買一套號稱「全自動產出 100 篇 SEO 文」的工具就一勞永逸(母題 A,那只會生出一堆 AI 味的垃圾稀釋你的品牌)。先建一份「怎樣算一篇好文」的驗收標準,每篇生成完拿它對一遍(母題 B)。然後品牌調性、產品數據、要不要發布這種事,留人把關,AI 負責把草稿跟資料準備到八成(母題 C)。
台灣電商老闆,今天就能動手的三件事
看完別只是點頭。三條母題,對應三個你今天就能試的動作:
► 動作一(對應母題 A,先砍):把你最常用的那個 AI prompt 叫出來,刪掉一半「以防萬一」的規則。 就是那些你當初為了某個極端狀況補上、後來再也沒用到的條款。在你想接第二個 AI 工具之前,先花十分鐘盤點現在這套:它的指示有幾條、有幾條是「以防萬一」、你在 Shopline 或 91APP 後台串了幾個自動化但其實沒人在看。你那個越寫越長的客服 GPT,十之八九不是不夠強,是被你塞爆了。先用乾淨,再談擴張。怕的話,動手前先複製一份備份。
► 動作二(對應母題 B,看數據):幫你的 AI 任務建一個小小的「驗收標準」。 不用搞得多專業,挑 5 到 10 個你真實會遇到的問題,每次調完 prompt 就拿這幾題跑一遍對答案。這就是 Day 2 那些 Evals 場講的精神:別再憑「感覺它好像變好了」做決定,用看得到的結果來判斷。對 prompt 還沒安全感的人,可以搭我之前寫的給天天用 AI 的人 4 個 Prompt 技巧一起看。
► 動作三(對應母題 C,留把關):把你的 AI 任務分成兩堆。 一堆是「錯了也沒差、改回來很快」的(寫商品文案草稿、整理客服常見問題),這種可以放手讓 AI 多跑。另一堆是「錯一次就回不來」的(金流設定、退款決策、對外的公開聲明、法務相關),這種一定要留人簽核、留得下軌跡。越貴、越不可逆,越不能全自動委派。
講個我自己的故事,因為這三件事我都用慘痛換來過。
早年超愛寫 SOP。每次出包就補一條規則,每次有人問就再寫一段說明,那份投放準則越長越厚,我還很得意,覺得自己把 know-how 都沉澱下來了。結果咧?沒人照著做。新人翻兩頁就放棄,老手嫌綁手綁腳,連我自己要查一件事都得滾半天滑鼠。那份「完整」的 SOP,最後變成一份沒人看的裝飾品。
後來我心一橫,把它砍到一頁,只留真正會影響成敗的那幾條判斷原則,其他全刪。
團隊反而動起來了。
以前我以為,把規則寫得越多越細,團隊就越不會犯錯。現在我才懂,過量的規則本身就是一種雜訊,它會把真正重要的那幾條淹沒。你給 AI 的 prompt,跟你給團隊的工作守則,犯的是同一種錯。
這也跟我之前在王董週刊談「Coding is Solved 之後」的主軸接得上:當「執行」越來越不值錢,你的價值會壓到「判斷」這一格上。判斷什麼該留、什麼該砍、什麼能放手、什麼要留把關,正是這種能力。
最後
這年頭大家都在比誰加得多。誰串的工具多、誰的 prompt 寫得長、誰又接了一個更新更強的模型。
但 Code with Claude 第二天,那 13 場真正在第一線把 agent 做上線的人,反覆在做的卻是相反的事。
他們在砍。他們在量。他們把刀留在自己手上。
模型會一直變強,這不用你操心。該你操心的是,當你的 AI 不聽話的時候,你的第一個念頭是「再加一條規則」,還是「我是不是塞太多了」。
換個念頭,差很多。
常見問題 FAQ
Q1:Code with Claude London 2026 Day 2 跟 Day 1 差在哪?
Day 1 偏「現況盤點」,是 24 場比較像產業 keynote 的演講,講模型進化到哪、產業瓶頸移到哪。Day 2 是 13 場 hands-on workshop,工程師現場示範「怎麼把 agent 真的做上線」,更實作、更具體。兩天主題零重疊,想看 Day 1 全 24 場整理可以看我另一篇導覽。
Q2:為什麼我的 prompt 寫越長,AI 反而越笨?
最常見的原因是「上下文污染(context pollution)」:指令一多,裡面常有你沒察覺的互相矛盾,模型會被搞糊塗。Day 2 的 StockPilot 案例就是 prompt 內兩條政策打架,導致它把促銷係數 3.1 算成 13.5。把 prompt 砍精簡、把矛盾清掉,通常比再補規則有效。提醒一下,那場 StockPilot 砍完後 eval 從 62% 升到 92% 是「單一案子」的數字,不保證你砍完也是這個幅度,但方向是對的。
Q3:Skill、工具(tool)、子 agent(subagent)差在哪,什麼時候用哪個?
簡單分:工具是 agent 的基本動作(讀檔、執行、搜尋);skill 是「需要時才載入」的知識包,平常不占空間;子 agent 是另開一顆腦去處理特定任務。Day 2 的建議是別過早動用子 agent,它只在「需要大量平行運算」或「需要全新視角去審查另一個 agent」時才划算,否則容易出現 Omni 講的那種「分裂大腦」溝通斷層。
Q4:我沒有工程團隊,這場開發者大會的東西用得上嗎?
用得上的是「思維」,不是工具本身。Skills、Managed Agents 這些對中小電商導入門檻還是高,但這三條母題你今天就能用:先砍不先加、憑指標不憑感覺、高風險留人把關。套在你的客服 GPT、後台自動化、prompt 設計上,完全不需要寫程式。
Q5:什麼是 AEO(答案引擎優化)?我做電商行銷要怎麼開始?
AEO(Answer Engine Optimization,答案引擎優化)是讓 ChatGPT、AI 搜尋摘要在回答使用者問題時,直接引用你的內容,跟傳統「衝 Google 排名」的 SEO 是不同層。要開始,可以參考 Day 2 的 AirOps 思路:建一條「發現主題 → 研究 → 撰稿 → SEO/AEO」的內容工作流,但在每個關鍵節點留人審核,並且先把品牌資訊整理成一份固定的「品牌知識庫」給 AI 讀,避免每次生成的調性都飄掉。
Q6:我怎麼判斷哪個 AI 任務可以放手自動化、哪個一定要人把關?
用一個很簡單的標準:問自己「這件事錯了,改回來有多痛?」。錯了沒差、改回來很快的(生商品文案草稿、整理客服常見問答、初步分類訂單),可以放手讓 AI 多跑,頂多事後抽查。錯一次就回不來、或牽涉錢與信任的(金流設定、退款決策、對外公開聲明、法務合約),一定要留人簽核,而且要留得下軌跡(可溯源)。這就是 Day 2 母題 C 講的「越貴、越不可逆,越不能全自動委派」,不用會寫程式也能直接套。
協作聲明與免責
這篇文章由王董與 AI 一起整理製作完成。文中引用的第三方資料、研究或工具都會標註來源名稱;若原始出處有公開連結,會以 [來源名稱](URL) 形式附上,方便你進一步查找。若文中內容與原始出處有任何出入,請以原文為準。
內容僅供參考與學習交流,不構成任何專業、商業或投資建議,請依自身情況判斷並自行承擔行動風險。文中提及的工具功能、數據與平台政策可能隨時間異動,請以各官方最新公告為準。



